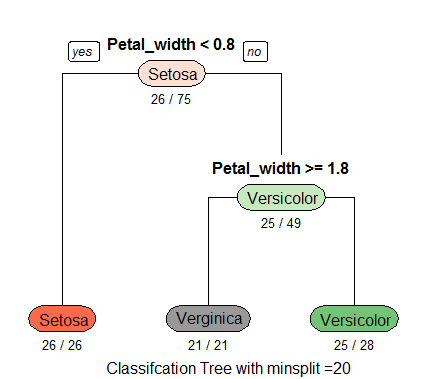
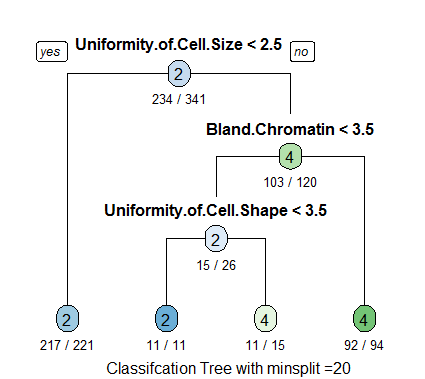
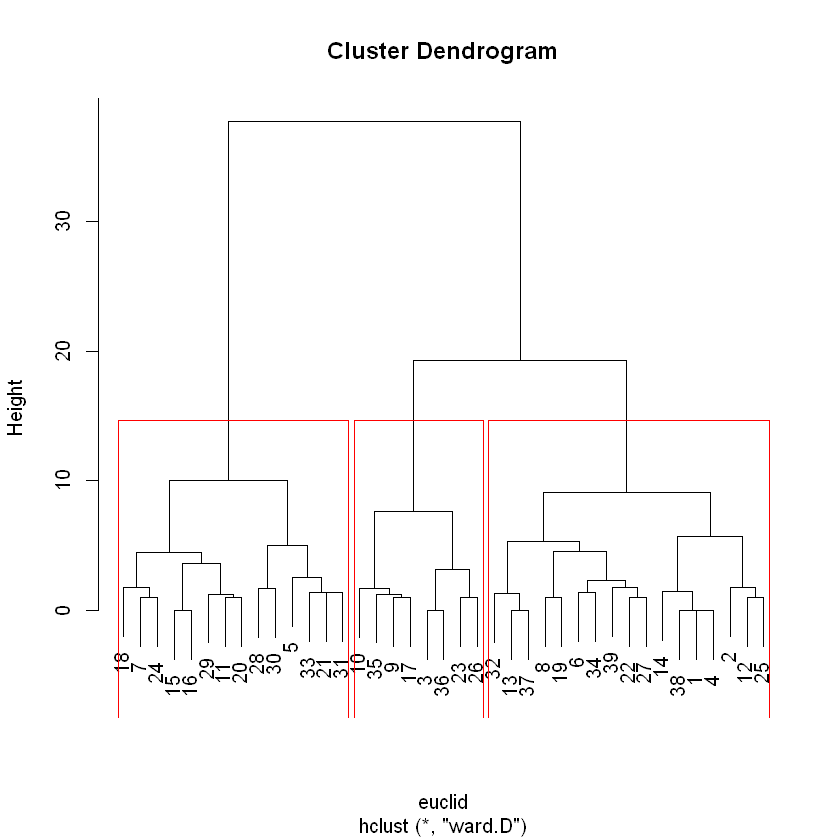
I’ve been working a lot with the R programming language recently and decided to take some time this weekend to refocus on my original goal of mastering Python. My plan all along has been to work in both languages, but my classes have put the emphasis on R. I decided to keep this weekend incredibly simple and just focus on the foundational components of the language that might be different from R; things like lists, if/else statements, for loops, things like that. It’s been a lot of fun, and I’ve enjoyed myself. Working in Jupyter Notebooks makes this process so incredibly easy because all I need to do is work in that IDE and execute the code right on the screen. RStudio is similar, but it’s more of a process, and it’s missing the overall “flow” that I think has attracted me to learning languages in the first place.
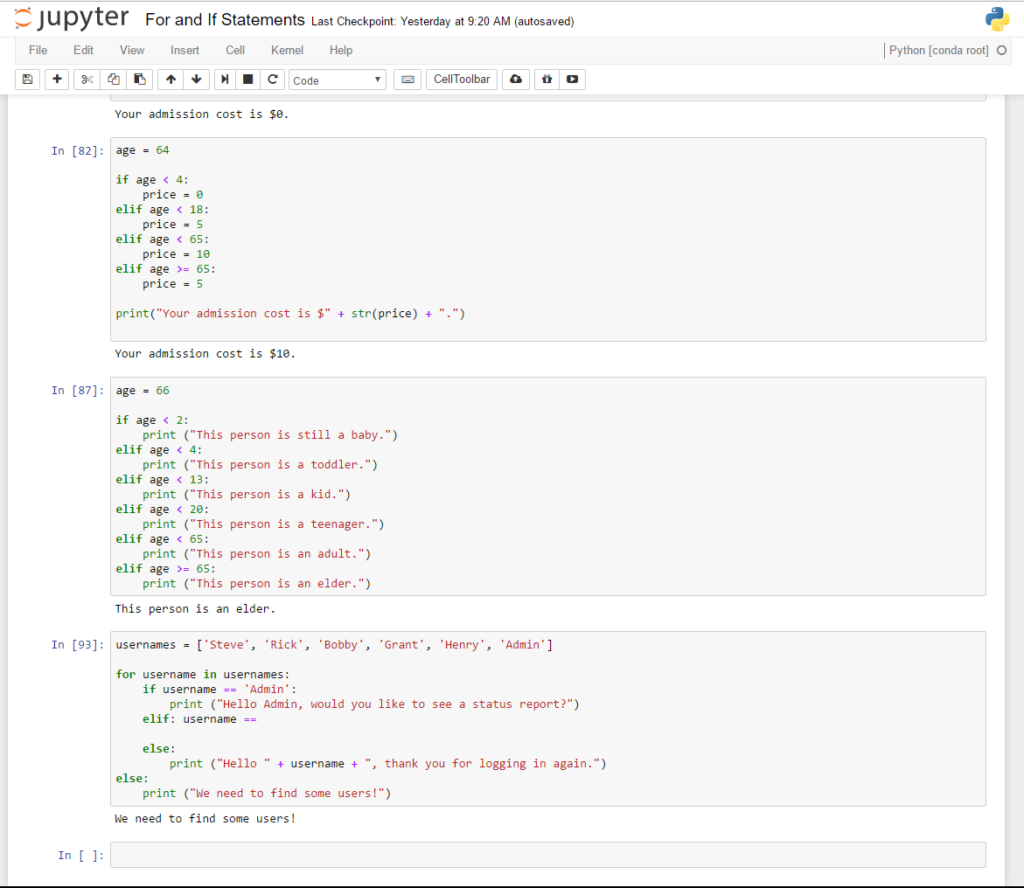
The primary resource I’ve been using this weekend has been a book called ‘Python Crash Course: A Hands-On, Project-Based Introduction to Programming‘ by Eric Matthes. Eric has done a great job of writing this book, keeping it simple, and building in instances where the reader can test the concepts and create some code themselves. As a beginner, I appreciate the challenge and opportunity to be creative and make something unique. I find that this opportunity to test your knowledge is missing in a lot of online learning environments, like Udemy. No disrespect to Udemy at all, it’s just a constraint of the online learning environment that is challenging to work around. Anyways, I chose this book because it promised projects working with data science, had high ratings on Amazon (for a good reason), and I needed something with a project-based approach where I could make mistakes, fail, and overcome the challenges when I actually experiment and apply the concepts.