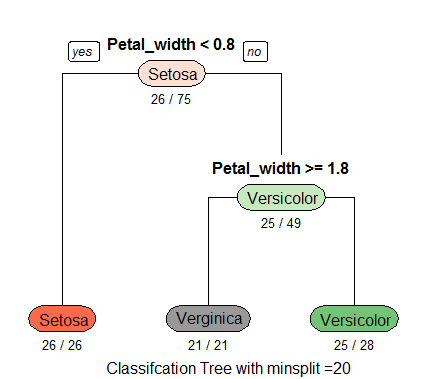
Recently in class, we’ve been building models called classification trees (also known as decision trees). There are a few different types of models used in decision tree learning, but classification trees allow for predictions of outcomes that are various classifications. The classic example is the iris dataset published in 1936 by Ronald Fisher. In this example, we can see how the outcome (species name) can be accurately predicted using a classification tree to create decision branches. See below:
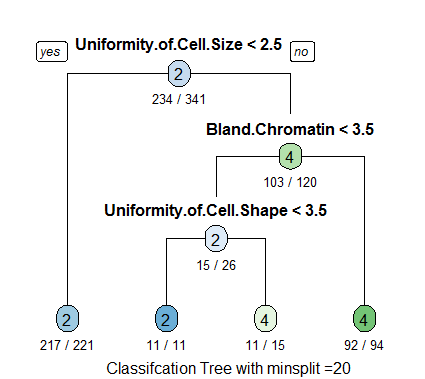
Classification trees have widespread applications across a variety of fields, but one of the more powerful examples are the implications it can have in health and medicine, where predictive modeling can be applied to large sets of data to hopefully help spot diseases and illnesses before they occur. We experimented with how these models could be built in our class, using anonymized data where the patient had a growth that was classified as either malignant or benign. Using these classification trees, a researcher (or software) can apply this trained algorithm or script to new data where the outcome is unknown and develop a plan to intervene with those patients (provide free screenings, contact patients that the algorithm predicts may be at risk, and so on). While these techniques shouldn’t replace regular visits and interactions with medical professionals, they can help an industry under enormous constraints be proactive in detecting and treating diseases before they cost the patient time, money, or even their lives.